动机
数据科学可以被概括为两个工作流:
- 模型开发
- 模型服务
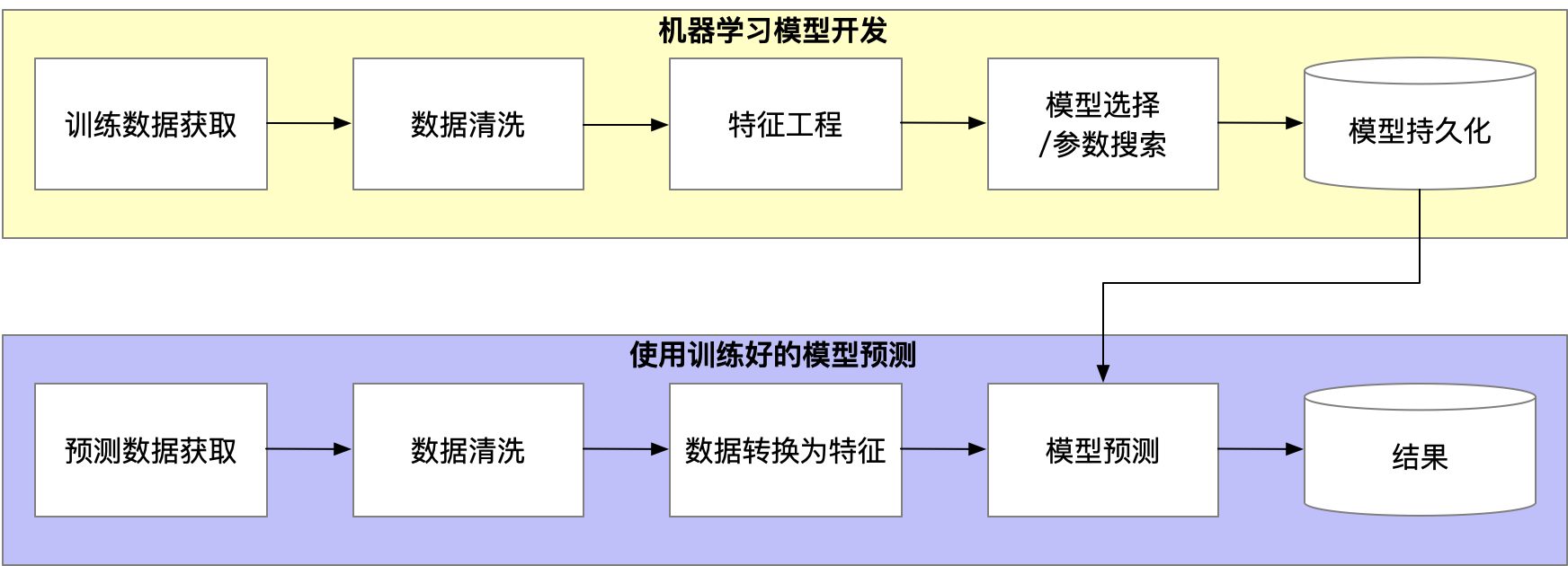
当数据科学团队较小的时候,不会面临太多的问题,所有事情都相对较好。
- 需要维护的模型较少
- 关于模型的知识在数据科学家的头脑中
- 每个人有跟踪流程的方法
但是,随着数据科学需求的增长,将面临新的问题
- 数据流的复杂度增加
- 大量的数据处理工作流
- 数据没有在标准化的流程中修改
- 管理复杂的流和定时任务变得不可管理

-
每个数据科学家有他们自己的工具集
- 一些喜欢tensorflow
- 一些喜欢R
- 一些喜欢Spark
- 一些喜欢所有

-
模型服务变得越来越难
- 不同的模板版本跑在不同的环境中
- 部署和回滚模型变得越来越复杂
-
问题出现很难回溯
- 数据科学家说是数据管道上的bug
- 数据工程师说是模型出了问题
- 变成了猫鼠游戏

幸运的是,许多同行都面临这些的问题有段时间了,这是一个大家都要解决的问题。
数据科学家:负责模型的开发
数据工程师:负责数据管道的开发
DevOps/DataOps/MLOps工程师:负责模型、数据管道和产品的生产化(由原型阶段部署到大规模的生产环境)
概念
因为技术功能变化了,因此基础设施也该对应的进化。
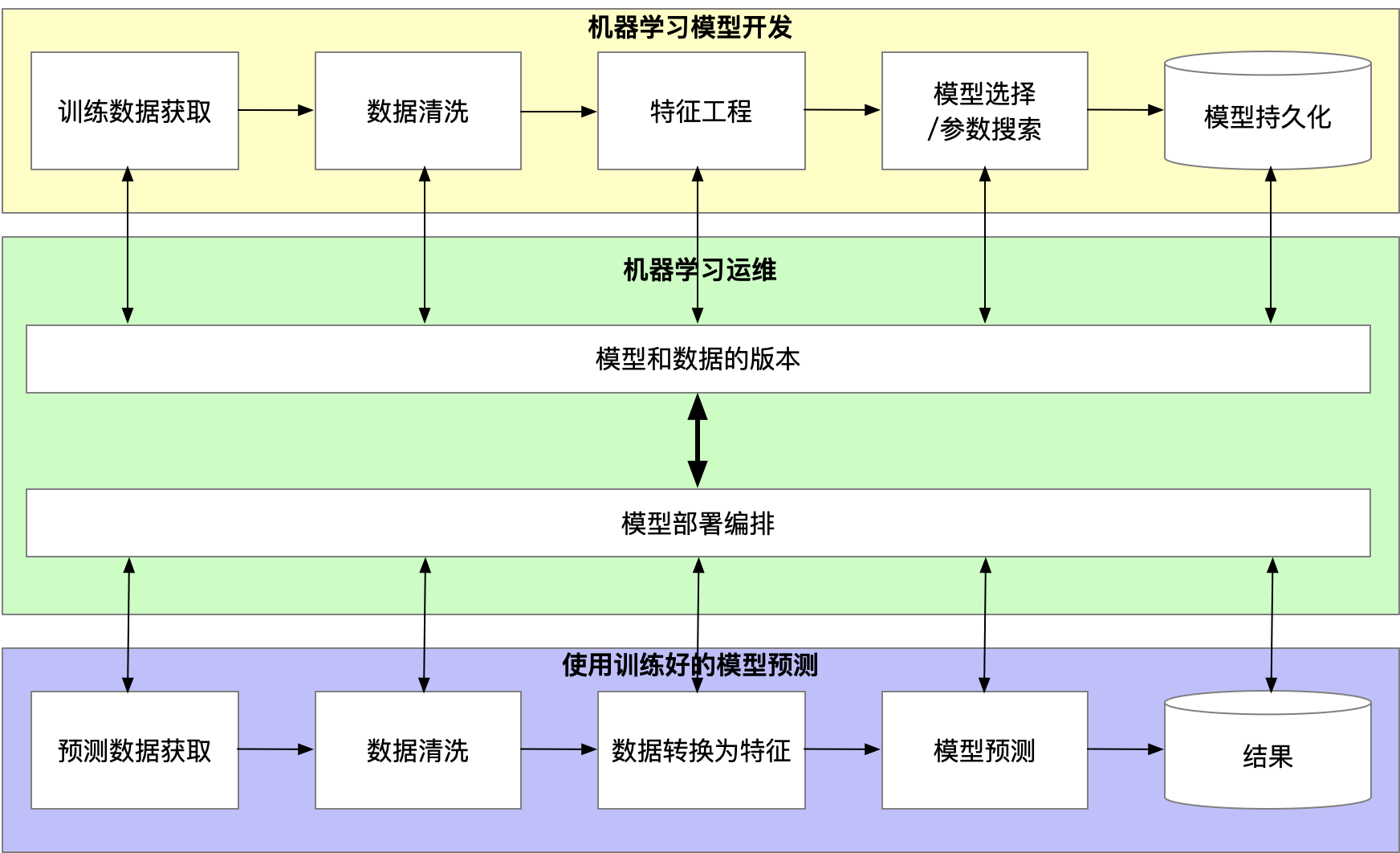
ML-OPS的两个原则:
- 重现性(Reproducibility)
- 编排
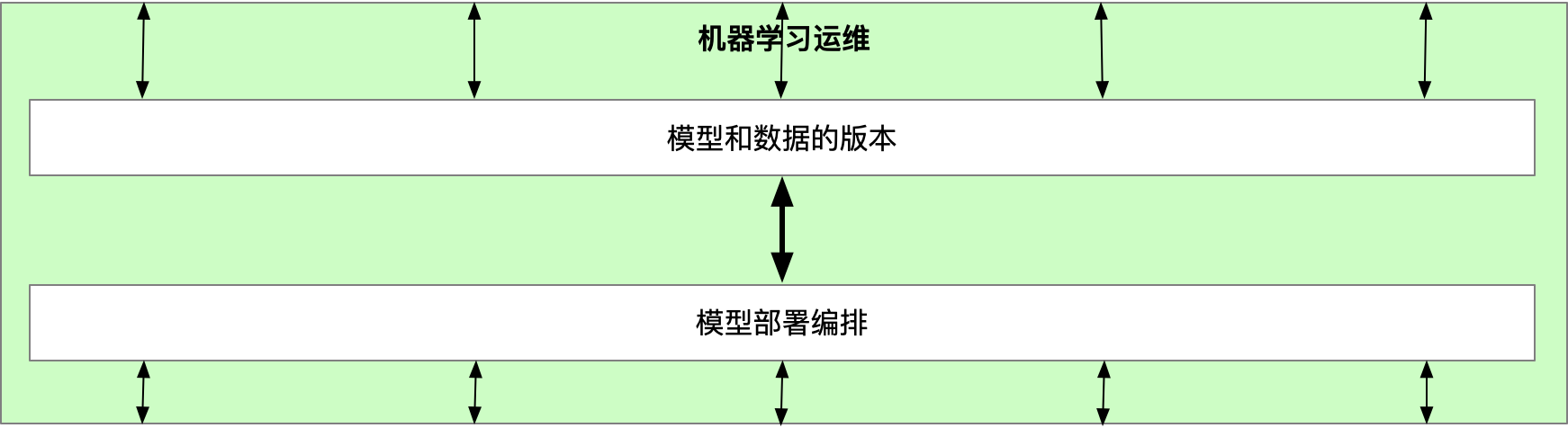
原则1:模型和数据的版本
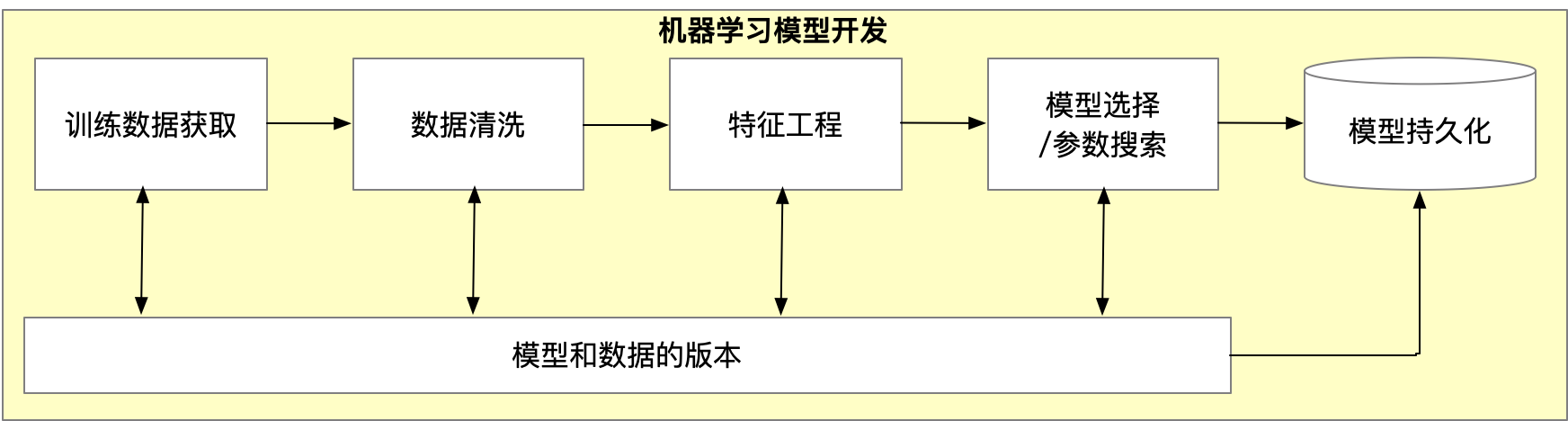
数据科学重现性的古老问题。
解藕管道中每一步。
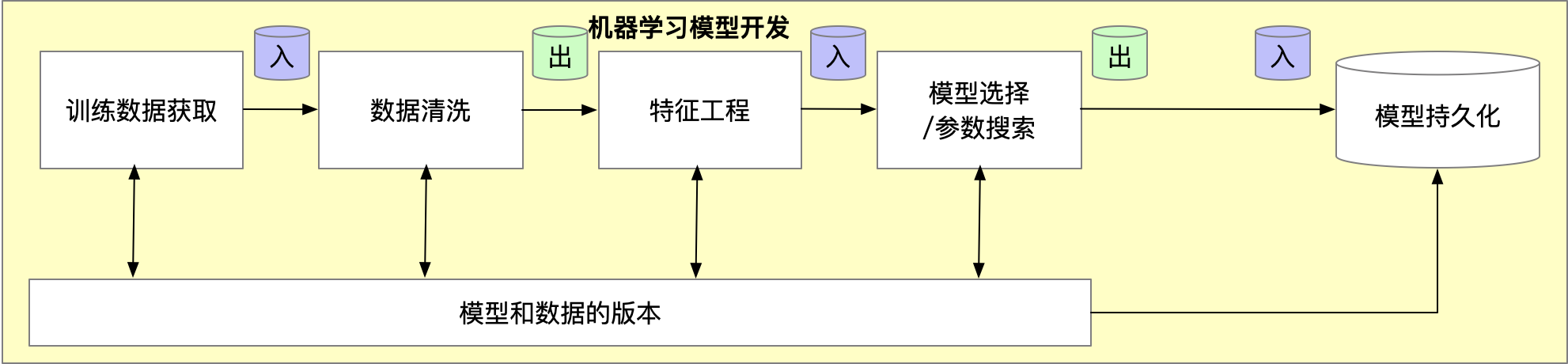
每一步都包含代码/配置,以及特定的数据数据输入和输出。
每一步的抽象:
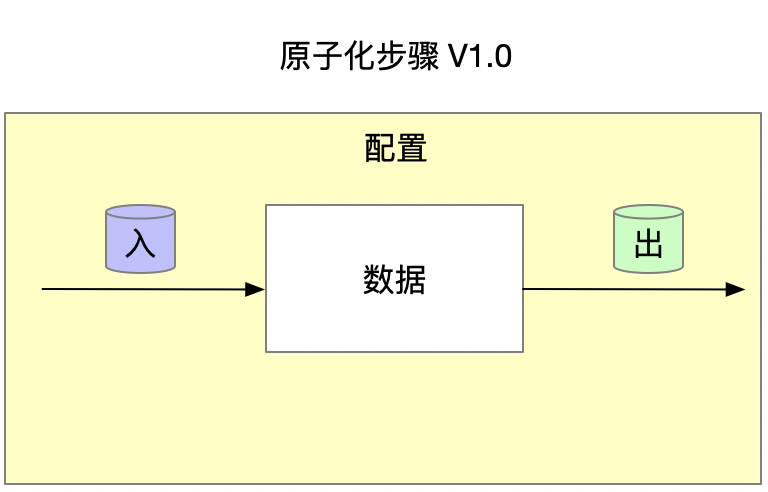
- 数据输入
$ cat data-input.csv
> Date Open High Low Close Market Cap
> 1608 2013-04-28 135.30 135.98 132.10 134.21 1,500,520,000
> 1607 2013-04-29 134.44 147.49 134.00 144.54 1,491,160,000
> 1606 2013-04-30 144.00 146.93 134.05 139.00 1,597,780,000
- 代码/配置
$ cat feature-extractor.py
> def open_norm_feature_extractor(df):
> feature = some_lib.get_open(df)
> return feature
- 数据输出
$ cat data-output.csv
> Open
> 0.57
> 0.59
> 0.47
在更高一个层面,我们可以把整个管道和数据流抽象出来。

重现性可以:
- 追踪错误的debug
- 透明化可以产生结果的步骤
- 组件模块化以便组件重用
- 抽象以支持多种库
- 强壮如果我们需要回到前一个发布
原则2:模型部署编排

覆盖生产环境中模型服务的复杂性。
Karpathy提到的软件2.0(即机器学习)
- 指定期望程序行为的一些目标(而不是写代码)
(e.g., “satisfy a dataset of input-output pairs of examples,”
or, “win a game of Go”)
- 写出代码的基本框架
(e.g., a neural net architecture) that identifies a
subset of program space to search,
- 在我们提议上使用计算资源,来搜索这个程序可以生效的空间。
监控,而不仅仅是debug日志
生产环境的质量控制过程是必要的,并且需要明确用例。
流程,一个枯燥的词但是有令人兴奋的好处
- 发生了什么
- 什么时候发生
- 为什么发生
- 如何发生
我们可以停止对demo之神祈祷。


这使数据科学家、数据工程师和devops/mlops工程师:
- 回溯问题
- debug问题
- 报告关键问题
分配计算资源
不同的服务需要不同的计算资源。通常有复杂的计算图。我们需要分配正确的计算资源。
这是一个复杂的问题。物理资源被抽象为通常的操作系统内核,“软件”可以是:
- ETL框架
- 基于HDFS的服务
- K8S集群
- 任何分布式框架!
不同的资源分配结果不同。



现有工具
原则1:重现性,模型和数据的版本
PMML
使用Sklearn2PMML导出PMML
from sklearn import datasets, tree
iris = datasets.load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
from sklearn_pandas import DataFrameMapper
default_mapper = DataFrameMapper(
[(i, None) for i in iris.feature_names + ['Species']])
from sklearn2pmml import sklearn2pmml
sklearn2pmml(estimator=clf,
mapper=default_mapper,
pmml="D:/workspace/IrisClassificationTree.pmml")
数据版本控制(DVC),数据科学项目的开源版本控制系统

git的一个分支,由iterative.ai构建,允许将数据、配置和代码通过版本管理系统分组。
添加你的数据
dvc add images.zip
联接数据输入、模型输出和代码
dvc run -d images.zip -o model.p ./cnn.py
添加仓库地址(这里是S3)
dvc remote add myrepo s3://mybucket
######Push到特定位置
dvc push
ModelDB
通过扩展函数本身用更显性的方式来跟踪库级别的输入、输出和配置。
普通的Sklearn:
def fit_and_predict(data):
model.fit(data)
preprocessor.transform(data)
model.predict(data)
使用modelDB:
def fit_and_predict(data):
model.fit_sync(data)
preprocessor.transform_sync(data)
model.predict_sync(data)
通常这会存储使用的所有步骤,与模型的结果和预测一起。这可以检查运行的模型。
PACHYDERM

Pachyderm是端到端的模型版本管理框架,允许管道的可重复定义。Pachyderm包含三个主要组件:
- Data仓库
- 在Docker容器中封装的处理步骤
- 联接步骤和数据仓库的管道
每个步骤包含数据输入和输出
构建一个使用sklearn SVM的鸢尾花分类器,训练管道,输入为训练的模型
创建仓库并且添加数据
创建仓库
$ pachctl create-repo training
$ pachctl list-repo
NAME CREATED SIZE
training 2 minutes ago 0 B
将数据(使用c标记)提交到仓库
$ pachctl put-file training master -c -f data/iris.csv
构建你的Docker镜像
PYTRAIN.PY
# pytrain.py
...import dependencies
cols = [ "Sepal_Length", "Sepal_Width", "Petal_Length", "Petal_Width", "Species" ]
features = [ "Sepal_Length", "Sepal_Width", "Petal_Length", "Petal_Width" ]
# Load training data
irisDF = pd.read_csv(os.path.join("/pfs/training",
"iris.csv"), names=cols)
svc = svm.SVC(kernel='linear', C=1.0).fit(
irisDF[features], irisDF["Species"])
# Save model to pachyderm /pfs/out
joblib.dump(svc, os.path.join("/pfs/out", 'model.pkl'))
Dockerfile
FROM ubuntu:14.04
...install dependencies
# Add our own code.
WORKDIR /code
ADD pytrain.py /code/pytrain.py
定义计算管道
{
"pipeline": {
"name": "model"
},
"transform": {
"image": "pachyderm/iris-train:python-svm",
"cmd": ["python3", "/code/pytrain.py",]
},
"input": {
"atom": {
"repo": "training",
"glob": "/"
}
}
}
可重现的管道

原则2:编排,模型部署编排
MLEAP

更深一层的模型序列化。MLeap是一个开源项目,用于抽象多种机器学习库的序列化和执行。
MLeap服务
运行server
$ docker run \
-p 65327:65327 \
-v /tmp/models:/models \
combustml/mleap-serving:0.9.0
加载模型
curl -XPUT -H "content-type: application/json" \
-d '{"path":"/models/<my model>.zip"}' \
http://localhost:65327/model
MLeap优化过的绑定

Seldon-core,企业级机器学习部署

更关注模型编排


处理CI、CD的挑战

可以开启使用Grafana的监控
