分类
Orange的很大一部分是关于机器学习的分类方法或者说监督式数据挖掘。这些方法依赖于带有类别标签实例的数据,类似于议会选举的数据。这是加载这个数据集的代码,显示第一个数据实例,并且显示它的预测类(共和党):
data = Orange.data.Table("voting")
data[0]
['n', 'y', 'n', 'y', 'y', 'y', 'n', 'n', 'n', 'y', '?', 'y', 'y', 'y', 'n', 'y', 'republican']
data[0].get_class()
<orange.Value 'party'='republican'>
学习器(Learners)和 分类器(Classifiers)
分类使用两个对象:学习器和分类器。学习器评估分类标签数据,并返回一个分类器。给定一个数据实例(一个特征向量),分类器返回一个预测的类别:
import Orange
data = Orange.data.Table("voting")
learner = Orange.classification.bayes.NaiveLearner()
classifier = learner(data)
classifier(data[0])
<orange.Value 'party'='republican'>
上面,我们读取数据,构建了一个[朴素贝叶斯学习器],给它这个数据集并构建了一个分类器,并用它预测了第一个数据的类别。我们在接下来的代码也采用同样的思路,来预测数据集中前5个实例的类别:
classifier = Orange.classification.bayes.NaiveLearner(data)
for d in data[:5]:
c = classifier(d)
print "%10s; originally %s" % (classifier(d), d.getclass())
这个脚本的输出如下:
republican; originally republican
republican; originally republican
republican; originally democrat
democrat; originally democrat
democrat; originally democrat
朴素的贝叶斯分类器在第三个实例上犯了个错误,但是其他的预测都是准确的。不需要惊讶,因为分类器就是在这个数据集上训练的。
概率分类
想要知道分类器分配的概率,比如说,民主党,我们需要使用额外的参数来调用分类器,这个额外的参数指定了输出的类型。如果指定了Orange.classification.Classifier.GetProbabilities,分类器将输出类别的概率:
classifier = Orange.classification.bayes.NaiveLearner(data)
target = 1
print "Probabilities for %s:" % data.domain.class_var.values[target]
for d in data[:5]:
ps = classifier(d, Orange.classification.Classifier.GetProbabilities)
print "%5.3f; originally %s" % (ps[target], d.getclass())
这个脚本的输出也显示出朴素贝叶斯分类器对于第三个数据的分类是多么糟糕:
Probabilities for democrat:
0.000; originally republican
0.000; originally republican
0.005; originally democrat
0.998; originally democrat
0.957; originally democrat
交叉验证
像我们上面这样在训练集上验证分类器通常都只是为了演示的目的。任何评估准确性的效能指标都需要在独立的测试集上进行。这个过程也称为交叉验证,多次运行的平均效果来预测,每次都使用来自原始数据集抽样的不同训练和测试子集:
data = Orange.data.Table("voting")
bayes = Orange.classification.bayes.NaiveLearner()
res = Orange.evaluation.testing.cross_validation([bayes], data, folds=5)
print "Accuracy: %.2f" % Orange.evaluation.scoring.CA(res)[0]
print "AUC: %.2f" % Orange.evaluation.scoring.AUC(res)[0]
交叉验证需要的是一系列学习器。效果的预测器(estimators)也返回一个分数的列表,一个学习器一个分数。因为上面的脚本只有一个学习器,因此使用的列表长度为1.脚本估计了分类准确性和ROC曲线下的面积。后者的分数相当高,表明朴素贝叶斯学习器在议会选举数据集上表现非常好:
Accuracy: 0.90
AUC: 0.97
一组分类器
Orange包含广泛的分类算法,包含:
-
logistic回归(logistic regression)(Orange.classification.logreg)
-
k-nearest neighbors (Orange.classification.knn)
-
支持向量机(support vector machines) (Orange.classification.svm)
-
分类树 (Orange.classification.tree)
-
分类规则 (Orange.classification.rules)
这些算法中的一些包含在了下面的代码中,下面的代码预估了测试数据的目标类型的概率。这次,训练和测试数据集是分开的:
import Orange
import random
data = Orange.data.Table("voting")
test = Orange.data.Table(random.sample(data, 5))
train = Orange.data.Table([d for d in data if d not in test])
tree = Orange.regression.tree.TreeLearner(train, same_majority_pruning=1, m_pruning=2)
tree.name = "tree"
knn = Orange.classification.knn.kNNLearner(train, k=21)
knn.name = "k-NN"
lr = Orange.classification.logreg.LogRegLearner(train)
lr.name = "lr"
classifiers = [tree, knn, lr]
target = 0
print "Probabilities for %s:" % data.domain.class_var.values[target]
print "original class ",
print " ".join("%-9s" % l.name for l in classifiers)
return_type = Orange.classification.Classifier.GetProbabilities
for d in test:
print "%-15s" % (d.getclass()),
print " ".join("%5.3f" % c(d, return_type)[target] for c in classifiers)
对于这五个数据,所观察的分类算法间没有很大的差异:
Probabilities for republican:
original class tree k-NN lr
republican 0.949 1.000 1.000
republican 0.972 1.000 1.000
democrat 0.011 0.078 0.000
democrat 0.015 0.001 0.000
democrat 0.015 0.032 0.000
下面的代码交叉验证了一些学习器。注意这些代码与上面代码的不同。交叉验证需要学习器,而在上面的脚本中,直接将数据给盗了学习器,并且调用了返回的分类器。
import Orange
data = Orange.data.Table("voting")
tree = Orange.classification.tree.TreeLearner(sameMajorityPruning=1, mForPruning=2)
tree.name = "tree"
nbc = Orange.classification.bayes.NaiveLearner()
nbc.name = "nbc"
lr = Orange.classification.logreg.LogRegLearner()
lr.name = "lr"
learners = [nbc, tree, lr]
print " "*9 + " ".join("%-4s" % learner.name for learner in learners)
res = Orange.evaluation.testing.cross_validation(learners, data, folds=5)
print "Accuracy %s" % " ".join("%.2f" % s for s in Orange.evaluation.scoring.CA(res))
print "AUC %s" % " ".join("%.2f" % s for s in Orange.evaluation.scoring.AUC(res))
在ROC曲线的面积方面Logistic regression获胜:
nbc tree lr
Accuracy 0.90 0.95 0.94
AUC 0.97 0.94 0.99
报告分类模型
分类模型是对象,暴露了结构的每个组成部分。例如,你可以用代码反转分类树,并且观察相关的数据实例,可能性和条件。但是,通常提供模型的文本形式输出就足够了。对于logistic回归和决策树,可以用下面的代码说明:
import Orange
data = Orange.data.Table("titanic")
lr = Orange.classification.logreg.LogRegLearner(data)
print Orange.classification.logreg.dump(lr)
tree = Orange.classification.tree.TreeLearner(data)
print tree.to_string()
logistic回归部分的输出为:
class attribute = survived
class values = <no, yes>
Feature beta st. error wald Z P OR=exp(beta)
Intercept -1.23 0.08 -15.15 -0.00
status=first 0.86 0.16 5.39 0.00 2.36
status=second -0.16 0.18 -0.91 0.36 0.85
status=third -0.92 0.15 -6.12 0.00 0.40
age=child 1.06 0.25 4.30 0.00 2.89
sex=female 2.42 0.14 17.04 0.00 11.25
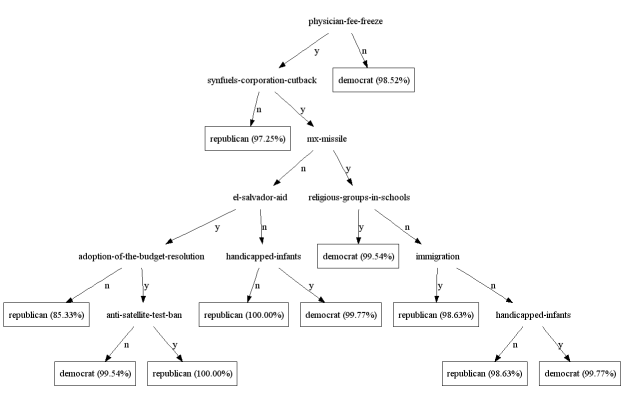
决策树可以用dot输出树形图:
tree.dot(file_name="0.dot", node_shape="ellipse", leaf_shape="box")
下图显示了树形图的样例: