Orange是一款底层基于C++,并且提供了Python接口的开源数据挖掘工具。与Sklearn,pyml这 类数据挖掘包相比,Orange的历史更加悠久,在上面实现的算法也更加丰富,此外,除了以python模块的形式使用之外,Orange还提供了GUI,可以用通过预先 定义好的多种模块组成工作流来完成复杂的数据挖掘工作。
Orange的发起最早可以追溯到1997年WebLab会议,在这个会议上人们提到了构建一个灵活的实验基准以便大家可以将自己的算法,实验结果放在上面,这些想法最终 催生了Orange项目。
Orange包含大量标准或非标准的机器学习和数据挖掘的算法,以及常规数据读写和操作,其底层的核心是由C++来实现的,同时Orange也利用python脚本来快速 实现新算法的原型以及一些不太要求执行时间的功能。 ##Orange中的数据 Orange使用一种专有的数据结构,扩展名为.tab,其实就是用tab分隔每个数据的纯文本。文档的第一行为属性的名称,用tab分隔,第二行为属性对应的数据类型, 包含连续性,间断型和字符型。第三行包含一些元信息,用于指明依赖的特征(分类),不相关的特征(需要忽略的特征)和元特征。
import Orange
data = Orange.data.Table("iris")
通过以上的代码,就可以获得一个Orange的数据表,数据表是Orange中基本数据单元(类似DataFrame在Pandas中的地位)。iris是Orange自 带的样例数据,其扩展名即为.tab。
Orange也可以读取其他格式的数据文件,比如csv,txt等。
data = Orange.data.Table("iris.csv")
以上就可以将iris.csv中的数据转换为Orange的数据表。iris.csv中是150个鸢尾花的记录,这个数据在数据挖掘的课程及工具中经常被引用作为分类和聚 类的样例数据。
让我们看一下iris这个数据表中的数据。
data.domain.variables
<Orange.feature.Continuous 'sepal length', Orange.feature.Continuous 'sepal width', Orange.feature.Continuous 'petal length', Orange.feature.Continuous 'petal width', Orange.feature.Discrete 'iris'>
在这个数据表中每条记录有5个属性
data.domain.features
<Orange.feature.Continuous 'sepal length', Orange.feature.Continuous 'sepal width', Orange.feature.Continuous 'petal length', Orange.feature.Continuous 'petal width'>
这5个属性中有四个属于特征,分别是花萼长度(连续变量),花萼宽度(连续变量),花瓣长度(连续变量),花瓣宽度(连续变量)
data.domain.class_var
Orange.feature.Discrete 'iris'
分类变量是一个间断变量
data.domain.class_var.values
<Iris-setosa, Iris-versicolor, Iris-virginica>
可以看到这150个鸢尾花是三种类型
每个Orange的数据表,是由Orange的data instant组成的list,每一个记录就是一个data instant
type(data)
Orange.data.Table
data[0]
[5.1, 3.5, 1.4, 0.2, 'Iris-setosa']
type(data[0])
Orange.data.Instance
data[0][0]
<orange.Value 'sepal length'='5.1'>
data[0][0].value
5.099999904632568
通过value属性可以获得一个属性的数值。
data.save("new_data.tab")
通过save方法可以将数据表输出为.tab的文件 ##用Orange进行分类 通过get_class方法可以获得Orange instance的对应的分类。对于iris这个数据集,就是具体的鸢尾花类型。
data[0].get_class()
<orange.Value 'iris'='Iris-setosa'>
在Orange中的分类任务提供了Learners和Classifiers两个对象。Learners通过对训练集的学习返回一个Classifier,Classif ier可以用来预测一个data instance属于哪个分类。
learner = Orange.classification.bayes.NaiveLearner()
classifier = learner(data)
classifier(data[50])
<orange.Value 'iris'='Iris-virginica'>
上面代码构建了一个朴素贝叶斯的learner,在iris数据集上应用learner构建了一个Classifier,并用它预测了一个样例数据。
classifier(data[50],Orange.classification.Classifier.GetProbabilities)
<0.000, 0.493, 0.507>
classifier(data[0],Orange.classification.Classifier.GetProbabilities).variable.values
<Iris-setosa, Iris-versicolor, Iris-virginica>
我们也可以看一下Classifier预测每个data instance是不同分类的可能性
data[50]
[7.0, 3.2, 4.7, 1.4, 'Iris-versicolor']
上面的Learner预测第51个样例数据为Iris-virginica,而其分类其实是Iris- versicolor,Classifier根据样例数据预测第51个样例有49.3%的几率属于Iris-versicolor, 有50.7%的几率属于Iris- virginica。通过Orange.evaluation.scoring.CA(Classification Accuracy)函数可以计算模型的分类准确度。
learners = [learner]
res = Orange.evaluation.testing.cross_validation(learners, data)
CA = Orange.evaluation.scoring.CA(res)
print CA[0]
0.92
可以看到应用朴素贝叶斯分类的模型,在训练集的正确率也只有92%。
让我们在Iirs数据集上应用多种判别算法,来看一下比较不同算法结果。
learners = [Orange.classification.bayes.NaiveLearner(),
Orange.classification.tree.TreeLearner(),
Orange.classification.neural.NeuralNetworkLearner(),
Orange.ensemble.forest.RandomForestLearner(),
Orange.classification.svm.SVMLearner()]
res = Orange.evaluation.testing.cross_validation(learners, data)
CAs = Orange.evaluation.scoring.CA(res)
for i,CA in enumerate(CAs):
print "{:s} CA is {:2%}".format(learners[i].name, CAs[i])
naive CA is 92.000000%
tree CA is 94.000000%
NeuralNetwork CA is 96.000000%
Random Forest CA is 96.000000%
sVM CA is 96.666667%
可以看到在默认的参数情况下,对于Iris数据集SVM的预测效果最好达到了96.7%,其次是神经网络和随机森林,决策树和朴素贝叶斯判别的效果较差。
##用Orange进行聚类 ###层次聚类
sample = data.select(Orange.data.sample.SubsetIndices2(data, 20), 0)
root = Orange.clustering.hierarchical.clustering(sample)
labels = [str(d.get_class()) for d in sample]
Orange.clustering.hierarchical.dendrogram_draw(
"hclust-dendrogram.png", root, labels=labels)
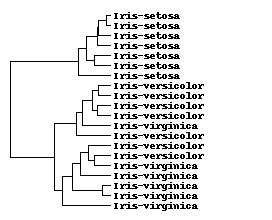
上面是官方给到的层次聚类的样例代码,通过这段代码可以将Iris进行聚类。代码中抽取了20个sample,如果分为三组的话,可以看到其中有3个数据的分类有误。 ###K-Means聚类
import random
km = Orange.clustering.kmeans.Clustering(data, 3)
sample = random.sample(range(150), 20)
for i in sample:
print km.clusters[i], data[i].get_class()
2 Iris-virginica
2 Iris-versicolor
0 Iris-setosa
0 Iris-versicolor
2 Iris-virginica
2 Iris-versicolor
2 Iris-virginica
2 Iris-virginica
0 Iris-setosa
2 Iris-virginica
2 Iris-virginica
2 Iris-versicolor
1 Iris-setosa
2 Iris-versicolor
1 Iris-setosa
2 Iris-versicolor
2 Iris-versicolor
2 Iris-virginica
2 Iris-virginica
1 Iris-setosa
同样是将iris分为三组,可以看到2对应Iris-setosa,0对应Iris-virginica,1对应Iris- versicolor,依然会有分组错误的情况。
在前面已经提到除了作为一个python模块外,Orange也提供了GUI进行数据挖掘,下图为层次聚类的一个工作流截图。
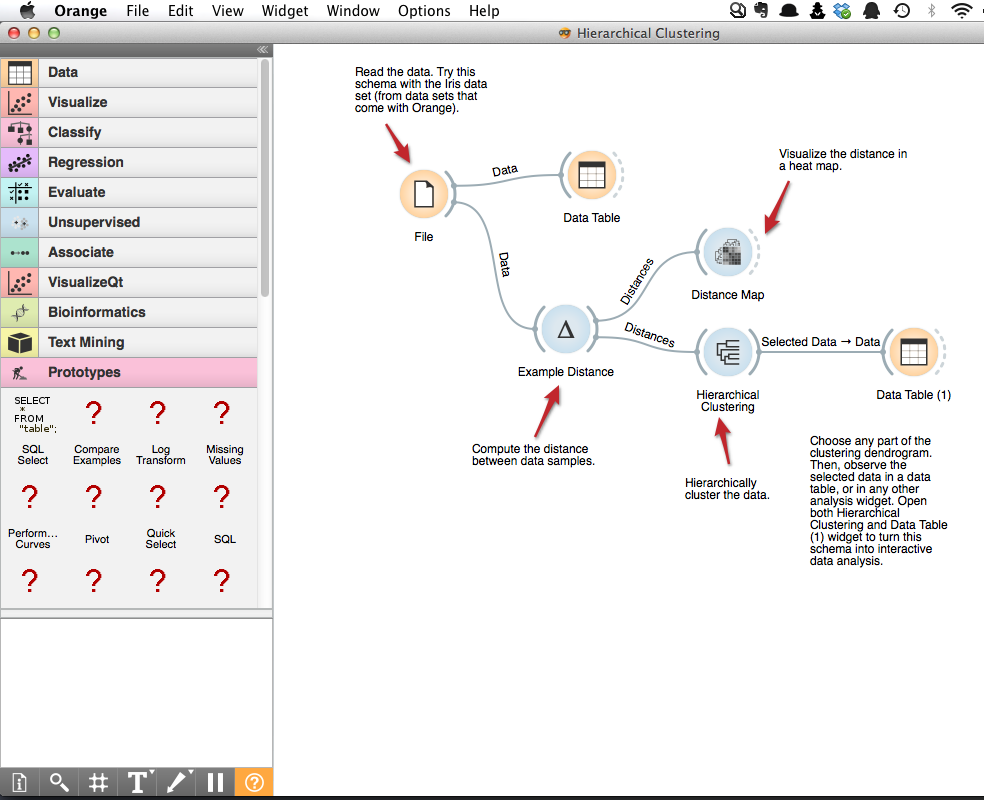
可以看到层次聚类的过程被分解为数据读取,计算距离,聚类,输出结果这几个步骤。通过在GUI中选取数据调整参数就可以进行层次聚类。