Uber在自家的博客上用两篇文章的篇幅介绍了他们自己的机器学习平台(Michelangelo)Meet Michelangelo: Uber’s Machine Learning Platform 和 Michelangelo PyML: Introducing Uber’s Platform for Rapid Python ML Model Development。最近看了一下这两篇文章,相关的内容节选如下。
系统架构
Michelangelo由开源系统和内置的组件混合组成。使用的主要的开源组件有HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, and TensorFlow。Uber通常倾向于使用可能的成熟开源选项,并且将会fork,自定义以及反向贡献,如果没有合适的开源项目,则会自主开发。
Michelangelo是构筑在Uber的数据和计算基础设置之上,这些基础设施提供了存储Uber所有交易和日志数据的数据湖,从所有Uber服务聚合日志数据的kafka broker,Samza流式计算引擎,Cassandra 集群和Uber自建的服务编排和部署工具。
机器学习工作流
几乎所有的Uber机器学习用例都存在相似的通用工作流,无论是分类还是回归问题,还是时间序列预测。这个工作流通常对实现是无感知的,因此可以很简单的扩展新算法类型和框架,例如更新的深度学习框架。也支持不同的不是模型,例如在线和离线的预测用例。
Michelangelo被设计为提供可扩展,可靠,可复制,易于使用和自动化的工具来解决以下六个步骤的工作流:
- 管理数据
- 训练模型
- 评估模型
- 部署模型
- 作出预测
- 监控预测
管理数据
寻找好的特征是机器学习最难的部分,构建和管理数据pipeline通常是完整机器学习方案成本最高的部分。
机器学习平台应该提供标准工具,用于构建数据pipeline来生成特征和标记数据集用于训练(再训练)以及只包含特征的数据集用于预测。这些工具应该与公司的数据湖或数据仓库,以及公司的自身数据服务系统深度整合。pipeline需要高效和可扩展,需要与数据流和数据质量的监控整合在一起,同时支持在线和离线训练与预测。理想的话,也应该有一种方式在团队内可共享的生成特征,以减少重复性工作和提高数据矢量。也应该提供强壮的警戒线和控制来鼓励和武装用户来接受最佳实践(即,很方便的保证训练和预测时,数据生成和准备流程是相同的。)
Michelangelo的数据管理组件被拆分为在线和离线pipeline。目前,离线pipeline被用于批量模型训练和批量预测任务,而在线pipeline用于在线低延迟的预测(未来会用于在线学习系统)。
另外,在数据管理层增加了一层,特征库,允许团队分享、发现以及在他们的机器学习任务上使用精心设计特征集。Uber的许多建模问题使用相同或类似的特征,使团队在内部项目间共享特征以及不同组织间的团队间分享特征很有价值。
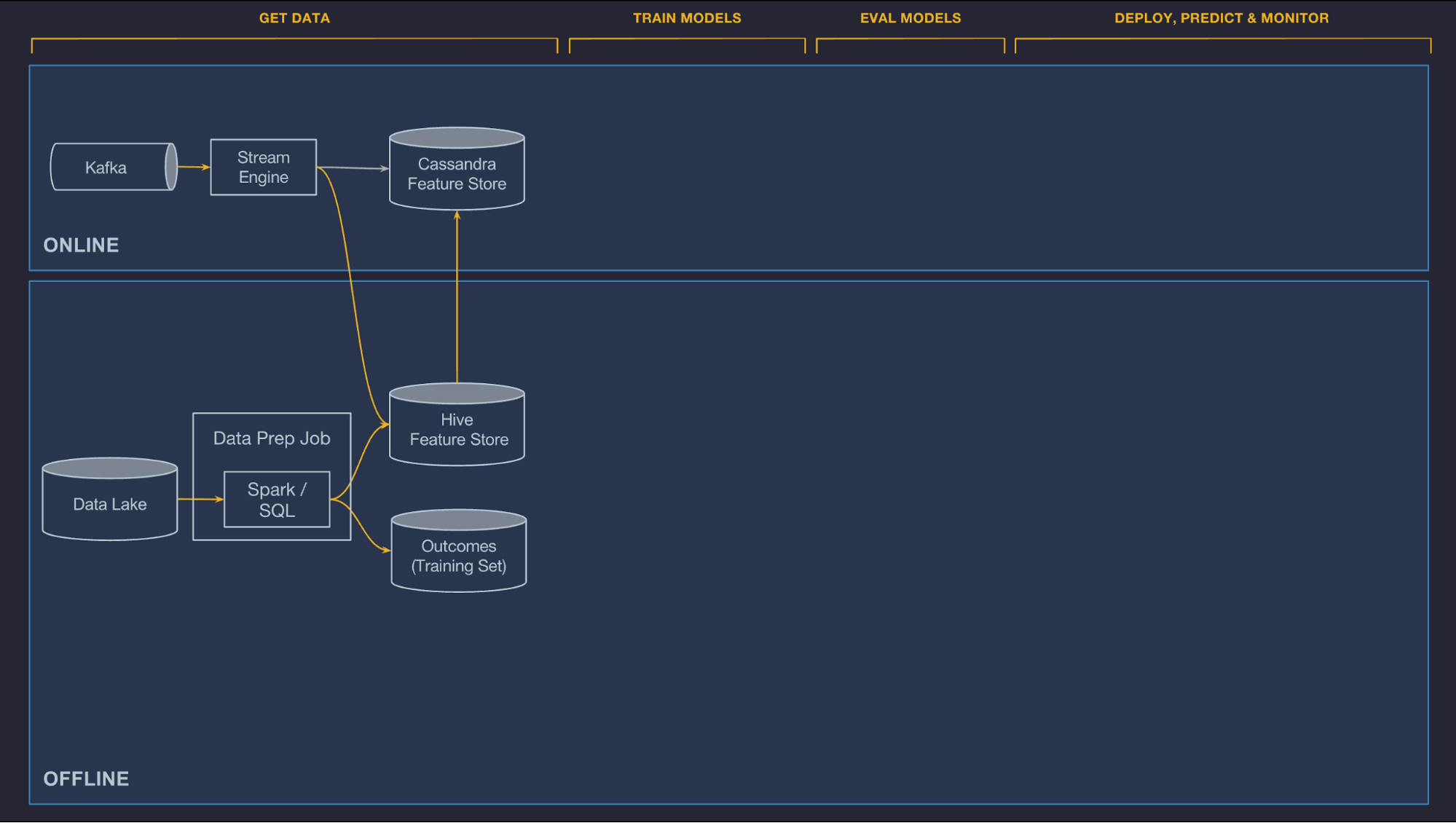
图1 数据准备pipeline推送数据到特征库和训练数据仓库
离线
Uber的交易和日志数据流入HDFS数据湖,可以方便的用Spark和Hive SQL来计算任务。Uber提供了容器,并且调度常规任务来计算特征,这些特征可以被用于特征项目或发布到特征库(见下面)在团队间共享,通过批量任务在调度器或触发器上运行并且与数据质量监控工具整合起来,可以快速的识别pipeline的数据质量下降,无论是因为本地或者上游的代码或者数据问题。
在线
在线部署的模型不能访问存储在HDFS中的数据,通常考虑性能的情况下直接从后端生产服务计算模型特征是很困难(例如,不可能直接查询UberEATS订单服务计算一个饭店一定时间的平均餐食准备时间)。反之,我们允许预计算在线模型需要的特征,并且存储在Cassandra,在预测时以很低的延迟读取出来。
Uber提供了两个方式来计算这些在线服务特征,批量预计算和近实时计算,概述如下:
- 批量预计算。第一个计算选项是进行批量预计算,并且定时将历史特征数据从HDFS加载到Cassandra。这种方式简单有效,通常对只需要每几个小时或一天更新一次的历史特征适用。这个系统保障了同样的数据和批pipeline用于训练和服务。UberEATS使用这个系统应用于“过去7天饭店的平均餐食准备时间”。
- 近实时计算。第二个选项是将相关指标发布到Kafka,然后运行基于Samza的流式计算任务来生成低延迟的聚合特征。这些特征随后被直接写入Cassandra提供服务,并且被记录在HDFS中用于后续的训练任务。与批系统类似,近实时计算保证相同的数据用于训练和服务。为了避免冷启动,还提供了工具来反向填入这些数据,并且通过在历史日志上运行批量作业在生成训练数据。UberEATS使用这类近实时pipeline在“饭店最近一个小时的平均餐食准备时间”这类特征上。
共享特征库
构建中心化的特征库很有价值,每个团队可以创建和管理自己团队使用的权威特征,并与其他团队分享。在更高的层面,它完成了两件事:
- 用户可以很简单的把他们构建的特征添加到共享特征库中,只需要添加一些在私有或项目使用场景基础上的一部分元数据(所有者,描述,SLA等)。
- 一旦特征进入了特征库,通过在模型配置中引用特征的简单权威名称就可以在线或离线很简单的消费这些特征。有了这些信息,系统会处理join正确的HDFS数据集来进行模型训练和批预测,并且从Cassandra获取正确的数据来进行在线预测。
目前,Uber的特征库中大约有10000特征,用于加速机器学习项目,并且各种团队随时都在添加新的特征。特征库中的特征每天都会被自动计算和更新。
未来,会构建一个系统,自动从特征库中进行搜索,并识别解决特定给定预测问题最有效和重要的特征。
特征选择和转换的领域特定语言(DSL)
通常由数据管道生成或有客户服务端发送的特征,不是模型需要的格式,并且有缺失值需要填充。与此同时,模型可能只需要特征的一部分。一些情况下,模型将时间戳转换为每天中的小时或者每周中的星期对于捕捉季节模型更有效。另外一些情况下,特征值可能需要标准化(即,减去平均值,除以标准差)。
要解决这些问题,Uber创建了建模人员在模型训练和预测的时候用来选择、转换和合并特征的DSL(领域特定语言)。这个DSL用Scala来实现。它是纯函数语言,带有常用函数的完整集合。有了这个DSL,客户团队有了添加自己的用户定义函数的能力。也有额外的函数从当前背景(在离线模型的场景下是数据管道,而在线模型场景下是来自客户端的当前请求)或未来特征库来抓取特征值。
需要注意的是DSL表达式是模型配置的一部分,相同的表达式被应用训练和预测,保证相同的特征集被生成和发送给模型。
训练模型
目前支持离线,大量分布式训练,包括决策树、线性和logistic模型,非监督模型(k-means)、时间序列模型和深度神经网络。